load( 'data/SensitivityProducts.RDATA')Sensitivity Analysis
A sensitivity analysis is a technique used to understand how changes in the inputs of a mathematical model or system affect the output. In the context of a model, such as a simulation or a statistical model, sensitivity analysis helps to identify which input parameters have the most significant influence on the results.
To begin load the model and dataset we will use for this workshop:
We will use the following packages:
library(randomForest)
library(tidyverse)
library(gtools)
library(ggplot2)In this workshop, we will prepare a sensitivity analysis for the model FCH4_F_gC.rf. Take a look at the model:
FCH4_F_gC.rf
Call:
randomForest(formula = FCH4_F_gC ~ P_F + TA_F + Upland, data = train, keep.forest = T, importance = TRUE, mtry = 1, ntree = 500, keep.inbag = TRUE)
Type of random forest: regression
Number of trees: 500
No. of variables tried at each split: 1
Mean of squared residuals: 4.321792
% Var explained: 35.76The model includes monthly precipitation (P_f), mean temperature (TA_F), and a binary indicator for upland (1= upland ecosystem and 0 = aquatic ecosystem).
Explore the conditions present within the dataset (fluxnet.new) used to build the model. First subset only the variables used in the final model:
model.vars <- fluxnet.new %>% as.data.frame %>% select( P_F, TA_F,Upland)Next, we will summarize the conditions within the dataset by quantiles (0.25, 0.5, 0.75): note that your categorical varibles need to be listed in .by=c().
model.vars.lower <- model.vars %>% reframe( .by= Upland, P_F = quantile(P_F, 0.25),
TA_F = quantile(TA_F, 0.25 ),
Quantile = as.factor(0.25)) %>% as.data.frame()
model.vars.median <- model.vars %>% reframe( .by= Upland,P_F = quantile(P_F, 0.5),
TA_F = quantile(TA_F, 0.5 ),
Quantile = as.factor(0.5)) %>% as.data.frame()
model.vars.upper <- model.vars %>% reframe( .by= Upland,P_F = quantile(P_F, 0.75),
TA_F = quantile(TA_F, 0.75 ),
Quantile = as.factor(0.75)) %>% as.data.frame()Combine the individual Summaries into one dataframe:
summary <- smartbind( model.vars.lower, model.vars.median, model.vars.upper)
summary Upland P_F TA_F Quantile
1:1 0 14.5905 1.609448 0.25
1:2 1 16.2000 2.099640 0.25
2:1 0 41.7950 10.157892 0.5
2:2 1 46.6680 10.859068 0.5
3:1 0 78.3985 17.060485 0.75
3:2 1 91.6260 17.147735 0.75Now, choose the variable you want to explore: TA_F
Look at the conditions present witing the dataset for TA_F
summary(fluxnet.new$TA_F) Min. 1st Qu. Median Mean 3rd Qu. Max.
-37.188 1.814 10.595 8.874 17.124 31.280 Look at the range in values for TA_F:
range(fluxnet.new$TA_F)[1] -37.18842 31.28010Access each individual range value:
range(fluxnet.new$TA_F)[1][1] -37.18842range(fluxnet.new$TA_F)[2][1] 31.2801Use the range to generate a sequence of values going from the highest to lowest:
TA_F.seq <- seq(range(fluxnet.new$TA_F)[1], range(fluxnet.new$TA_F)[2], by=5 )Create a dataframe:
TA_F.seq.df <- data.frame(TA_F = TA_F.seq )Next we will take the summary, remove the values for TA_F and replace is with the generated range:
TA_F_1AT <- summary %>% select(-TA_F) %>% cross_join(TA_F.seq.df)In this dataframe, all other variables in the model are held at their quantile values and only temperature varies across the range of values observed. This approach is “one-at-a-time”. We choose one variable to vary and hold all others at a specific value. Often the mean is chosen but using the 0.25 , 0.5, and 0.75 quantile helps to visualize what the model would predict across conditions.
Next, use the predict() function to predict values into the dataframe (TA_F_1AT) with the simulated conditions:
TA_F_1AT$PRED <-predict(FCH4_F_gC.rf , newdata = TA_F_1AT)
TA_F_1AT$PRED [1] 0.7865243 0.7849535 0.7849535 0.7863125 0.7915485 0.7938221 0.7999815
[8] 0.8049531 0.8573231 1.0604947 1.5308568 3.7154677 4.4405273 5.5544100
[15] 0.2840847 0.2840847 0.2840847 0.2841673 0.2833294 0.2859127 0.2846756
[22] 0.2908040 0.3133371 0.4528563 0.4795861 0.7387009 1.2891996 2.3624352
[29] 0.9599767 0.9599767 0.9599767 0.9601269 0.9602617 0.9624025 0.9571700
[36] 0.9776828 1.0225842 1.2624965 1.9266091 3.7791711 5.2229525 5.5206278
[43] 0.4368570 0.4368570 0.4368570 0.4368570 0.4368613 0.4474668 0.3249978
[50] 0.3315233 0.3450498 0.4880674 0.5654118 0.8090723 1.1766667 1.5957777
[57] 0.9608859 0.9608859 0.9608859 0.9610361 0.9618341 0.9640564 0.9618201
[64] 0.9784727 1.0238619 1.2011973 1.6773282 3.2341428 4.0571488 4.3363714
[71] 0.3662076 0.3662076 0.3662076 0.3662076 0.3662119 0.3768174 0.2958994
[78] 0.2985805 0.3224997 0.4540422 0.5588751 0.6855452 0.9679276 1.1272437Lets look at the predictions.
ggplot() + geom_point(data =TA_F_1AT , aes( x=TA_F, y=PRED) )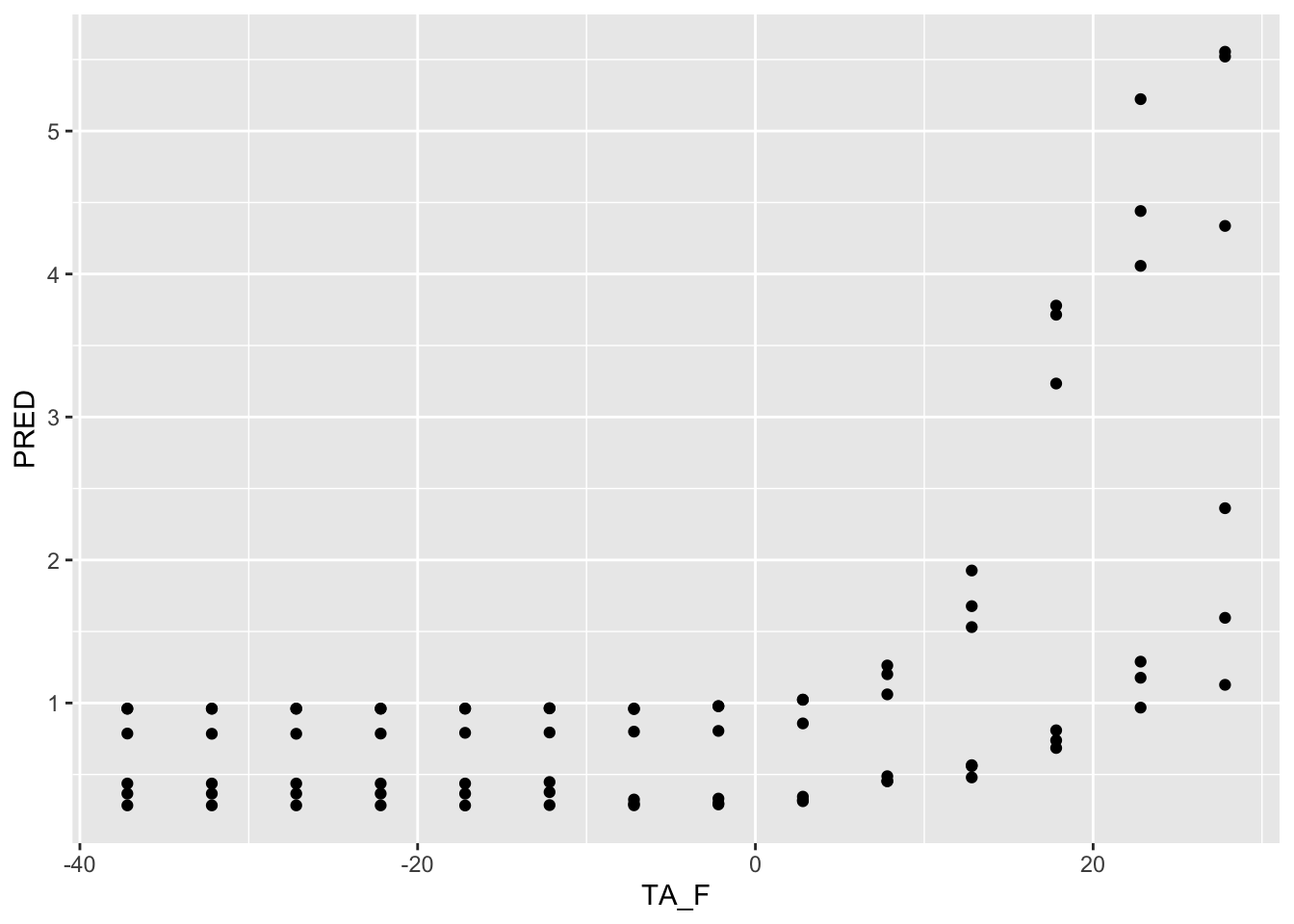
Use geom_smooth to visualize the general relationship:
ggplot() + geom_smooth(data =TA_F_1AT , aes( x=TA_F, y=PRED) )`geom_smooth()` using method = 'loess' and formula = 'y ~ x'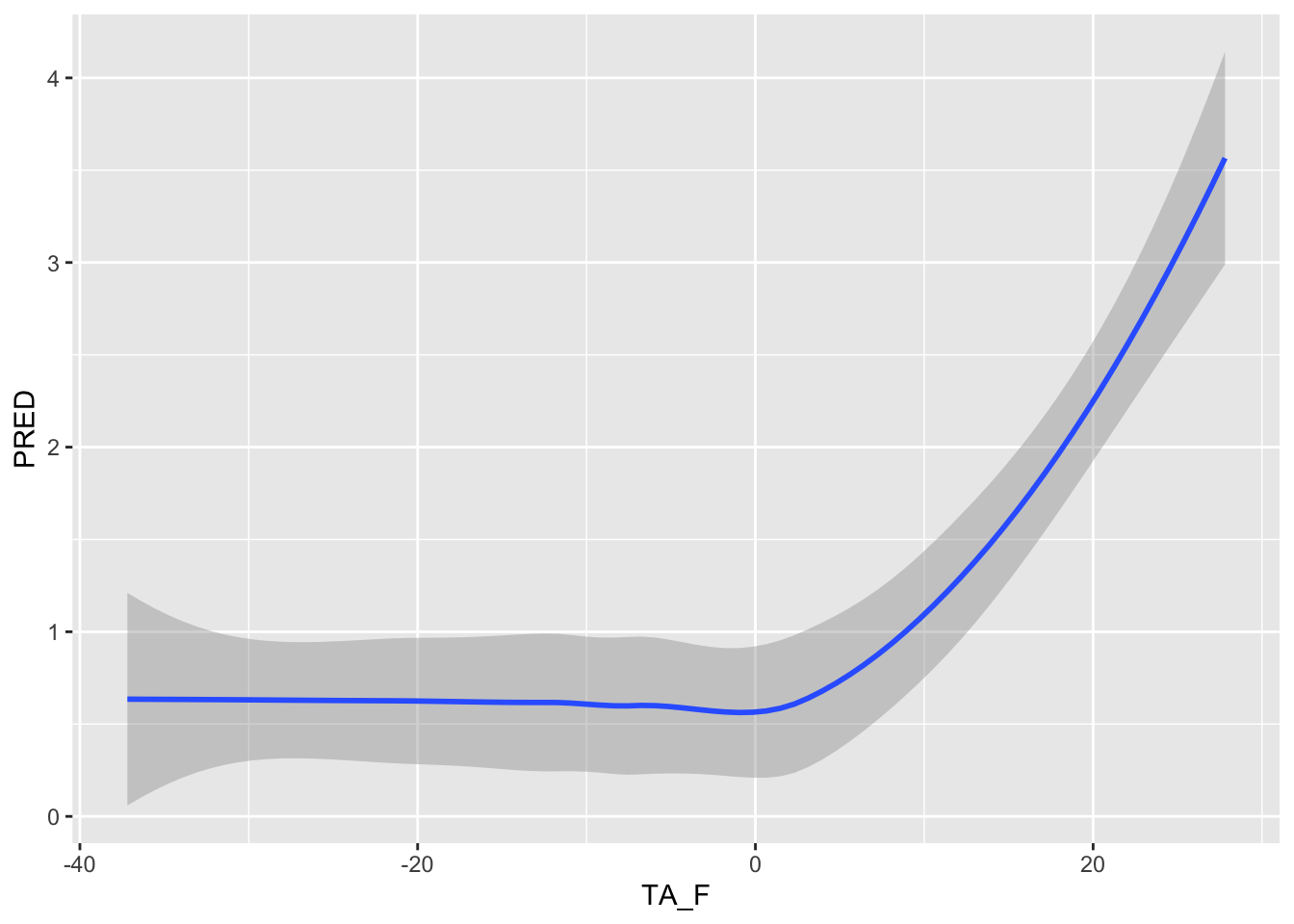
Look at the predictions by Quantile and by the Upland indicator:
ggplot() + geom_line(data =TA_F_1AT , aes( x=TA_F, y=PRED, color=Quantile, group=interaction(Quantile, Upland), linetype =Upland) )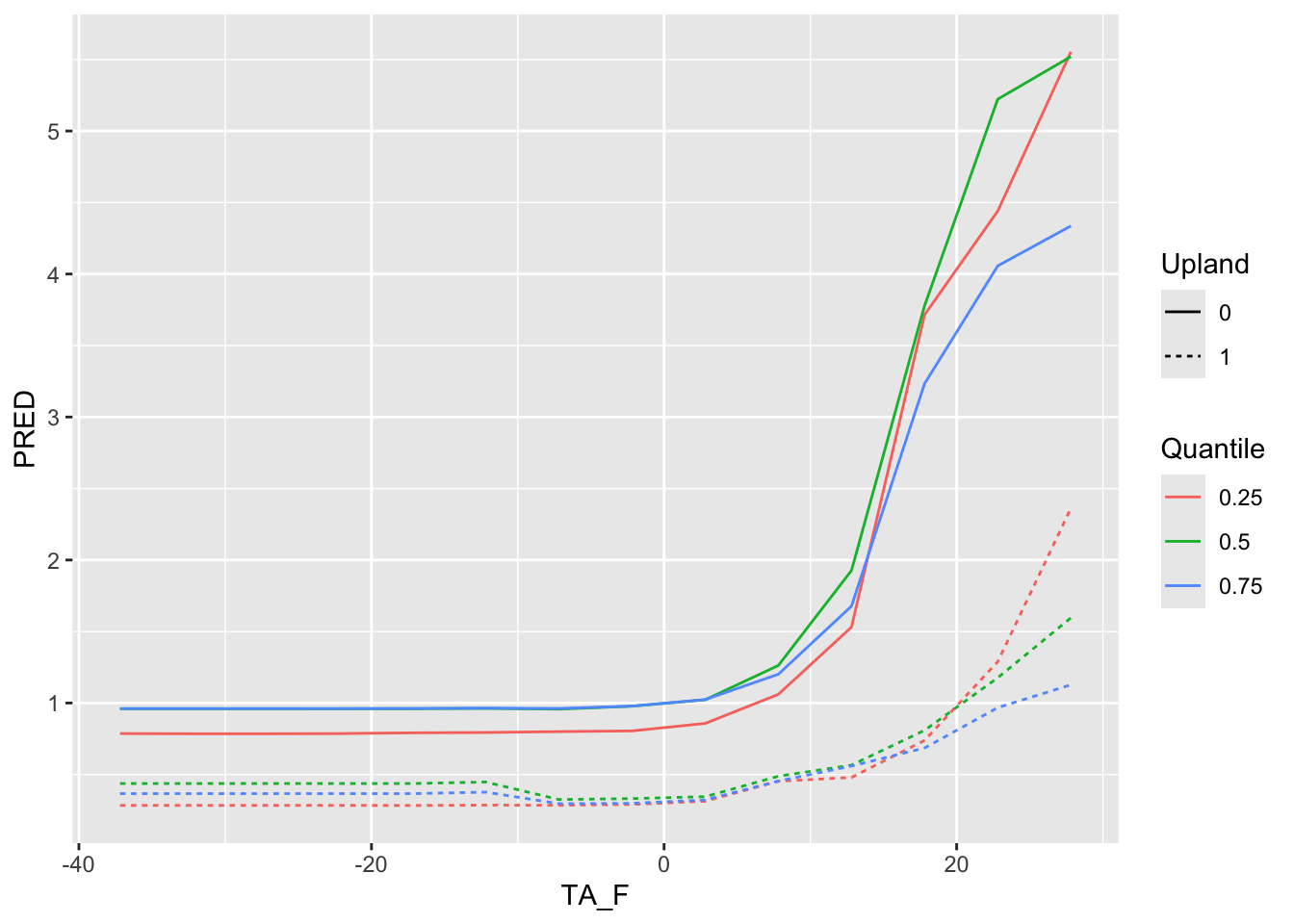
Now explore the next variable: PA_f
summary(fluxnet.new$P_F) Min. 1st Qu. Median Mean 3rd Qu. Max.
0.00 15.49 43.31 69.37 82.85 1094.02 range(fluxnet.new$P_F)[1] 0.000 1094.017range(fluxnet.new$P_F)[1][1] 0range(fluxnet.new$P_F)[2][1] 1094.017P_F.seq <- seq(range(fluxnet.new$P_F)[1], range(fluxnet.new$P_F)[2], by=100 )
P_F.seq.df <- data.frame(P_F = P_F.seq )
P_F_1AT <- summary %>% select(-P_F) %>% cross_join(P_F.seq.df)
P_F_1AT$PRED <- predict(FCH4_F_gC.rf , newdata = P_F_1AT)
ggplot() + geom_point(data =P_F_1AT , aes( x=P_F, y=PRED) )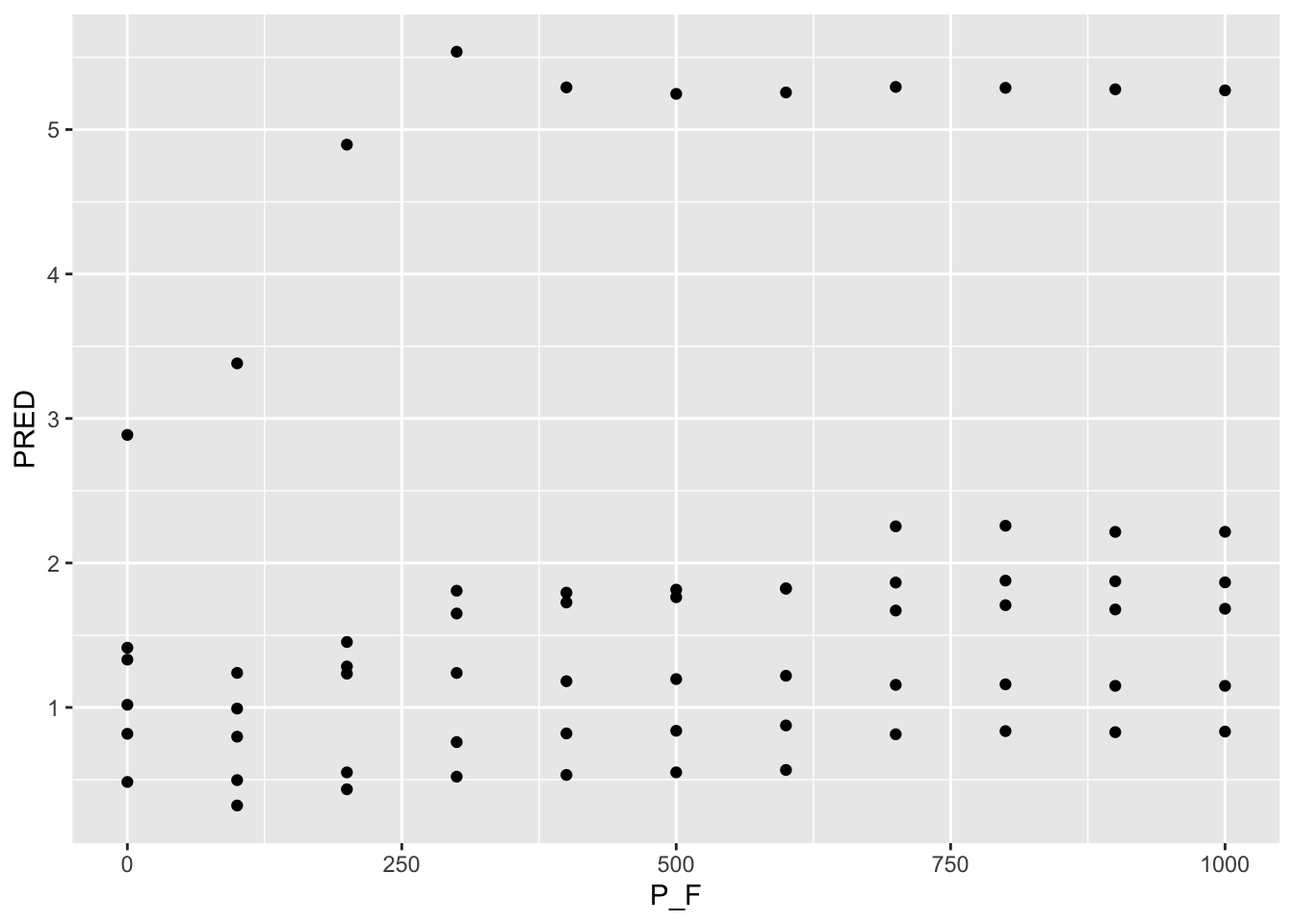
ggplot() + geom_smooth(data =P_F_1AT , aes( x=P_F, y=PRED) )`geom_smooth()` using method = 'loess' and formula = 'y ~ x'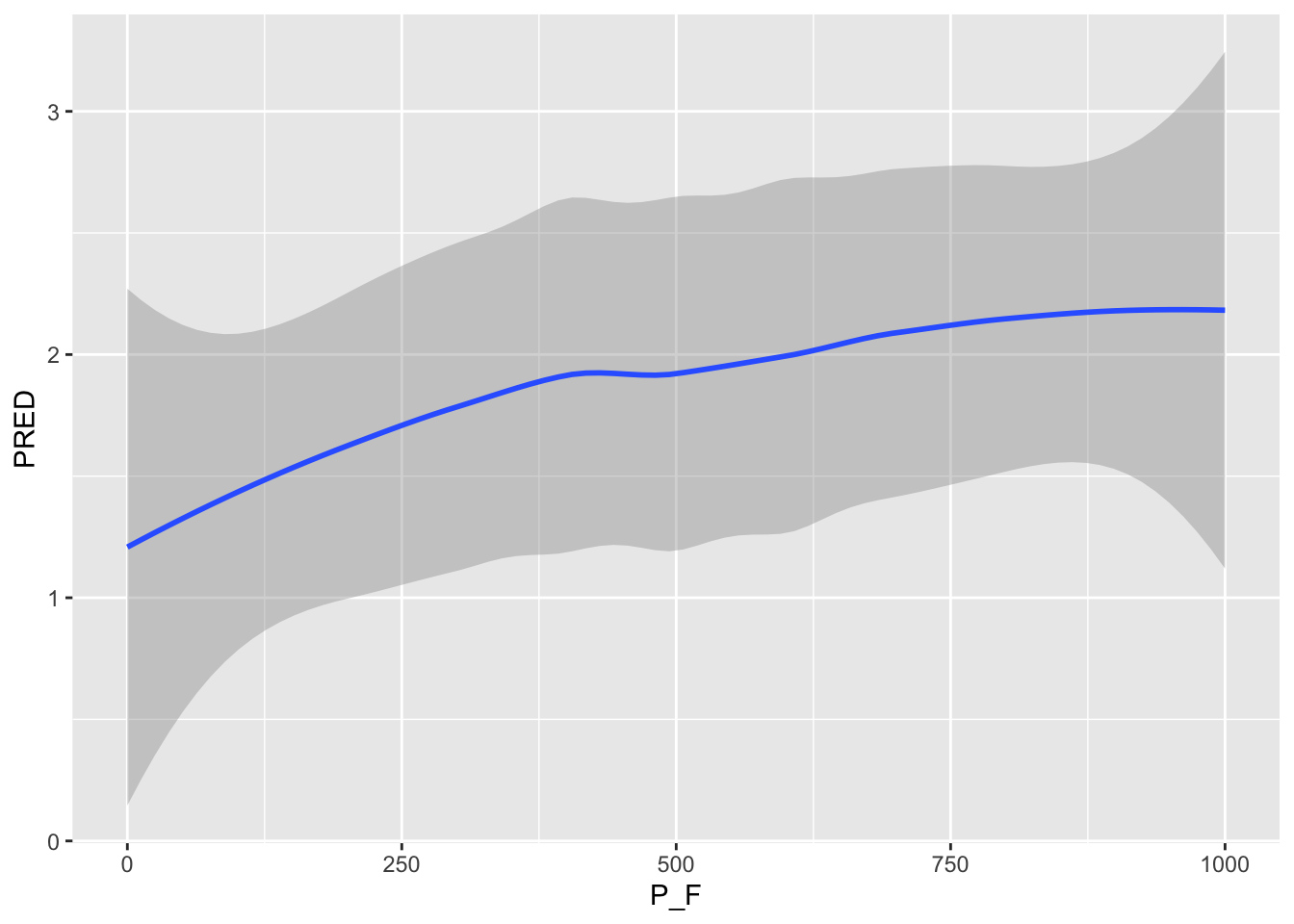
ggplot() + geom_line(data =P_F_1AT , aes( x=P_F, y=PRED, color=Quantile, group=interaction(Quantile, Upland), linetype =Upland) )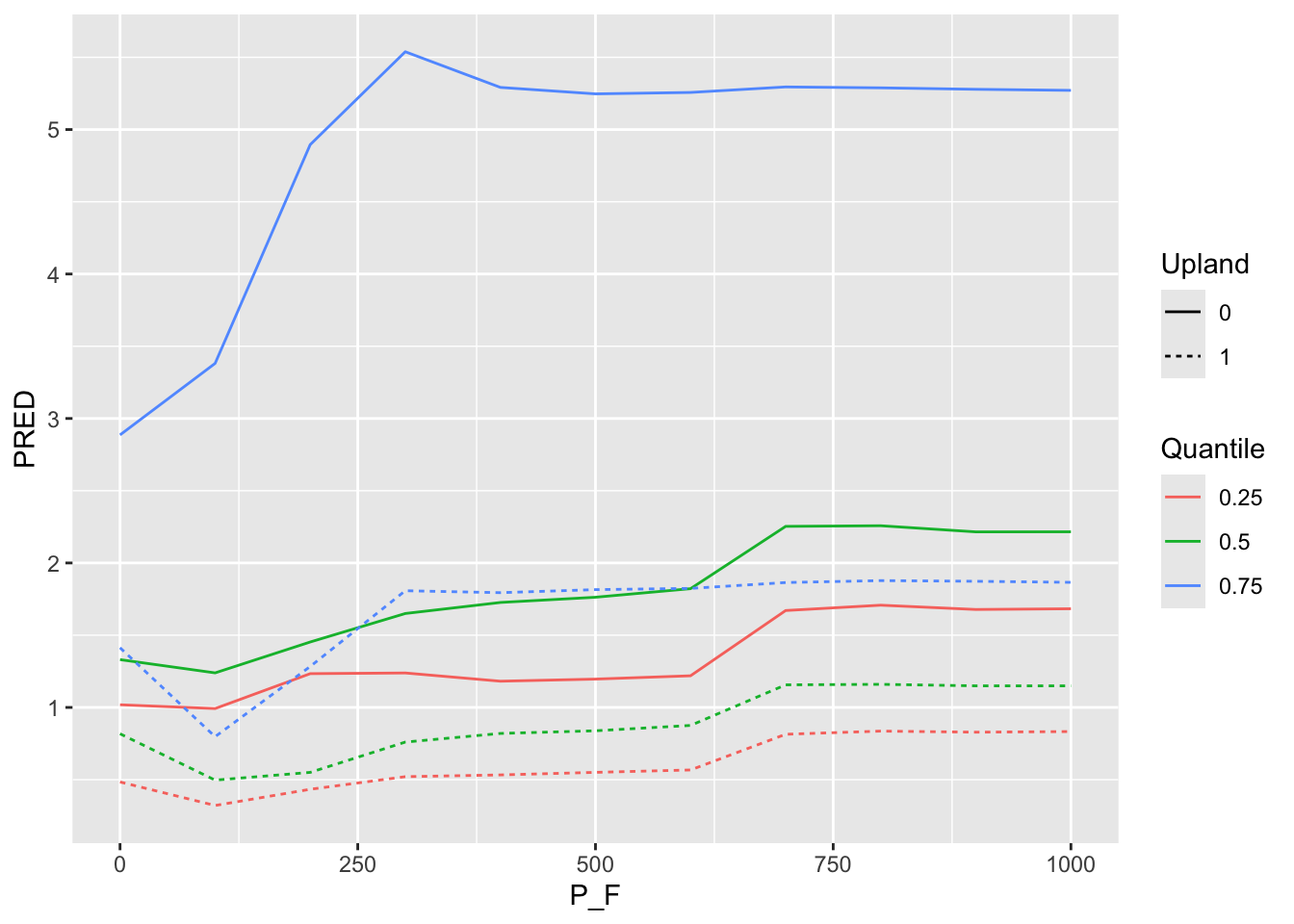
Use this same workflow to explore the sensitivity of your groups project’s model. Please provide a presentation explaining how you fit your model (mtry?, ntree?) and how variables where selected (forward versus backward selection). Describe your final model results (variables in the final model, their importance, the %Var, observed versus predicted for testing and training data), including a correlation plot, variance importance plots, and sensitivity analyses. This report will develop into the methods and results portion of your final project.